EnumeratorとEnumerator::Lazyの違い
はじめに
Ruby 2.0では、Enumerable#lazy というメソッドと、その返り値である Enumerator::Lazy が導入されました。
この記事では、Enumerable#lazy と Enumerator::Lazy によって無限リストをmapできることを紹介します。
また、Enumerator と Enumerator::Lazy の本質的な違いを説明します。
遅延リストとは
遅延リストですが、Haskell などの一部の関数型言語では一般的に使われているもので、 遅延評価といって、値が必要になるまで計算しないことによって、無限に続くリストも扱うことができるというものです。
無限リストをmapする
普通にやってみるとダメ
次のような無限リスト(無限の長さを持つ Range オブジェクト )を map する式[1]を考えてみます。
この式は実行が終わりません。
[1] pry(main)> (1..Float::INFINITY).map{|n| n*2}.first(5)
## => (実行が終わらない...)
[1]の式のmap では、Enumerable#map が呼ばれます。
Enumerable#map は配列Arrayを返り値とするメソッドなので、無限の長さの配列を作ろうとして、処理が終わらなくなります。
lazy を付けてみると動く
Enumerable#lazy を使って、次の式[2]ように無限リストを map によって処理することができます。
[2] pry(main)> (1..Float::INFINITY).lazy.map{|n| n*2}.first(5)
## => [2, 4, 6, 8, 10]
[2]の式のmap では、Enumerator::Lazy#map が呼ばれます。
Enumerable#lazy は リスト(Array,Rangeなど)を 遅延リスト Enumerator::Lazy に変換するメソッドです。
Enumerator::Lazy#map も Enumerator::Lazy を返すメソッドです。
したがって、(1..Float::INFINITY).lazy.map{|n| n*2} 全体が Enumerator::Lazy になります。
Enumerator::Lazy の中身は、force(to_a)やfirstが呼ばれるまでは、値は評価されません。
最後に Enumerator::Lazy#first が呼ばれた時に、ようやく値を評価するので、無限リストを扱うことが出来ます。
Enumerable#map と Enumerator::Lazy#map
ここで注目するべきポイントは、[1]と[2]の map は全く別のメソッドで、定義されている場所も返り値も異なっていることです。
特に、[2]では、結果を即座に配列にしないで、遅延リストとして保持しているという点が重要です。
- [1]のmap:
Enumerable#map->Array - [2]のmap:
Enumerator::Lazy#map->Enumerator::Lazy
Enumerator も遅延リスト
Ruby2.0 から新しく遅延リストが登場したかのように誤解してしまうかもしれませんが、古くからRubyにはEnumeratorというクラスがあります。
例えば、IO#each_line はブロックを省略すると、ファイルの各行を順に yield するような Enumerator を返します。
次のような例では、ファイルを全て読み込まずに、最初の10行だけを処理することができます。
つまり、IO#each_line はファイル全てを読み込みません。
File.open("log.txt") do |f|
puts f.each_line.first(10)
end
驚くかもしれませんが、Enumerator::Lazy と Enumerator はどちらも遅延リストです。
すこし工夫すれば、Enumerator でも無限リストを処理することもできます。これは最初の例と全く同じ結果になります。
つまり、Enumerator でも無限リストを処理できます。
Enumerator.new{|y|
(1..Float::INFINITY).each{|n|
y << n*2
}
}.first(5) # => [2, 4, 6, 8, 10]
このように、Enumerator でも無限リストを処理することもできますが、Enumerator::Lazy を使ったほうが、
map によって直感的で読みやすく短いコードで表現できます。
Enumerator::Lazy の真の目的
Enumerator::Lazy と Enumerator の 2つのクラスの本質的な違いは、
メソッドチェーンで呼び出される map が Array を返すか、Enumerator::Lazy を返すかどうかにあります。
2つのクラス自体の機能としては、ほとんど違いはありません。
言い方を変えれば、Enumerator::Lazy の真の目的は lazy版のmap や select を再定義することにあります。
lazyを付けるとmapの動作が変わる不思議な仕様
なぜ、lazy を付けると map や select の動作が変わる不思議な動作にしたのか? と疑問に思った人もいると思います。
Enumerable#lazy を作った Yutaka HARA さんが、るびまで答えていました。
Enumerableモジュールには、lazy 版がほしくなるようなメソッドがmap、select、reject、drop、… とたくさんある。- 全部追加すると、
Enumerableモジュールのメソッドが増えすぎる。 Enumerator::Lazy名前空間を提供することによって、「lazy」という メソッド名をひとつ追加するだけで lazy 版のmapやselectなどが使えるようにした。
リンク先の記事でも、Enumerable#lazyは「map や select などの lazy 版を提供するための名前空間を提供するメソッド」というのがより正確な説明になると述べられています。
まとめ
- 遅延リストによって、無限リストなどをシンプルに扱うことができる
Enumerator::LazyとEnumeratorの本質的な違いは、mapやselectなどのメソッドの挙動の違いにあるEnumerator::Lazyの真の目的は lazy版のmapやselectを再定義すること
補足
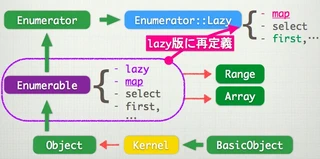
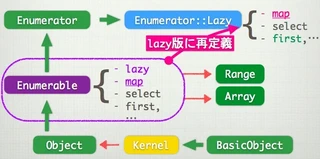
クラスの継承関係
Enumerator::LazyやEnumerator、Enumerableなどの継承関係が複雑なので、図にまとめました。
遅延リストが使える場面
最後に遅延リストが有効に使える場面を考えてみました。
- 数学的に無限長の数列を扱いたい
- TwitterのTimeLine
- 巨大なファイル(の一部だけ処理したい)
特に、数学的な処理には強力だと思います。
map や first メソッドを使って、数列の長さを気にせずに、各処理を抽象化できるのが強力だと思います。
Qiita もやってます
同じ内容の記事を Qiita にも投稿しました。
Related Posts
Rubyで関数型プログラミングをするための ImmutableList gem を公開
Immutable な LinkedList を Ruby で使うためのライブラリです。
Books
ブログ執筆者の著書


