9月9日(土)~9月10日(日)に諏訪湖で開催されたレイトレ合宿5‽に参加しました!
レイトレ合宿は完全自作のレイトレーサーを走らせて画像の美しさを競うイベントです。
去年に初参加させていただき、今年で2回目の参加になります。去年の参加報告はこちらです。
私はRustでパストレーサ(Hanamaruレンダラー)を実装して、こんな感じの画像をレンダリングしました。
今年は16人中9位なので、去年の13人中10位よりは進歩しました!

↑リンクをクリックするとオリジナルの可逆圧縮の画像になります。
ソースコードはGitHubに公開しています(スターください)。
こちらは合宿当日のプレゼン資料です。
今年もレンダリング分野の最先端で活躍されている方々がたくさん参加されていました。
趣味でRedqueenレンダラーを開発し、仕事でAutodeskのArnoldレンダラーを開発されている大垣真二さん、 ファーストオーサーの論文がSIGGRAPH 2017にアクセプトされた研究者のHisanari Otsuさんなどが参加されていました。 他にもt-pot.comの今給黎隆さん、 project-asura.comのPocolさんなど、 CGの勉強をしたことがあれば必ずお世話になるような有名なサイトの管理人たちも参加されていました。
この記事では、自作のパストレーサの解説やRust初心者によるRustの感想を書きます。
当日の様子はPentanさんの記事にまとめられています。 興味がある方はそちらもご覧ください。
Hanamaruレンダラーの主な仕様
ポリゴンとの衝突判定をBVHで高速化したり、薄レンズモデルによる被写界深度を入れたり、IBLしたりしました。
- ポリゴンメッシュに対応
- objファイルの読み込みに対応
- BVHで衝突判定を高速化
- albedo / roughness / emissionをテクスチャで指定可能
- PBR用のテクスチャ素材などを使える
- 薄レンズモデルによる被写界深度(レンズのピンぼけ)
- Image Based Lighting(IBL)
- CubeMapに対応
- 対応マテリアル
- 完全拡散反射
- 完全鏡面反射
- 金属面(GGXの法線分布モデル)
- ガラス面(GGXの法線分布モデル)
シーンの解説
宝石をランタイム時にプロシージャルに配置してシーンを作りました。
- うさぎのモデル
- Stanford BunnyをMeshLabで1000ポリゴンにリダクション
- 宝石のモデル
- 知り合いにモデリングしてもらいました。感謝
- 拡大・平行移動・回転の変換行列を実装
- 重ねて置けない制約をつけつつ、乱数でいい感じに配置(43個)
- seed値を変えればシーンも変化する(ランタイム時にプロシージャルに配置)
- 床はPBR用のテクスチャを拝借
- CubeMap用のテクスチャも拝借
高速化の取り組み
今年の合宿では4分33秒以内にレンダリングするルールでしたので、いくつかの高速化に取り組みました。
ちなみに出力画像の解像度についてはルールはありませんが、目標を高くするために1980x1080を採用しました。
パストレーシング・レイトレーシングの高速化のアプローチはいくつかあります。
- 衝突判定の高速化
- モンテカルロ積分のサンプリングの効率化
- 並列処理
それぞれ何を行ったのか簡単に紹介します。
衝突判定の高速化
レイトレの実行時間のほとんどは衝突判定が占めるので、これを高速化するのは効果的です。
衝突判定の高速化としてはBVH(Bounding Volume Hierarchy)を実装しました。
シーン内のすべてのオブジェクトを総当りで衝突判定せずに、空間分割によって衝突判定の回数を減らします。
具体的な実装などについては、お餅さんの記事を参考にしました。
お餅さんの記事では、Surface Area Heuristicsという手法で評価関数をつかった領域分割をしていましたが、 今回は実装の時間が無かったので、領域の最長辺を軸に選んで要素数で2分割する実装にしました。 単純な分割方法ではありますが、総当りと比較すれば十分に高速化できました。
全探索だと251.251 sec
— がむ (@gam0022) 2017年8月14日
軸をランダムに選んでポリゴンを2等分するBVHだと 36.28 sec
AABBの最長辺を軸に選んでポリゴンを2等分するBVHだと 28.424 sec
シーンを構成するオブジェクトとして、ポリゴンメッシュ、球体、立方体の3種類に対応しました。 シーンを構成するオブジェクトに対してのBVHだけでなく、ポリゴンメッシュを構成するメッシュに対してもBVHを構築しました。
モンテカルロ積分のサンプリングの効率化
パストレーシングはレンダリング方程式をモンテカルロ法をつかって解を求める手法です。
モンテカルロ積分のサンプリングを効率化すれば、より少ないサンプリング数でノイズの少ない収束した結果を得ることができます。
サンプリングの効率化のための手法としては、重点的サンプリング、多重重点的サンプリング、Next Event Estimationなどがあります。
詳しくはShockerさんの資料を参照してください。
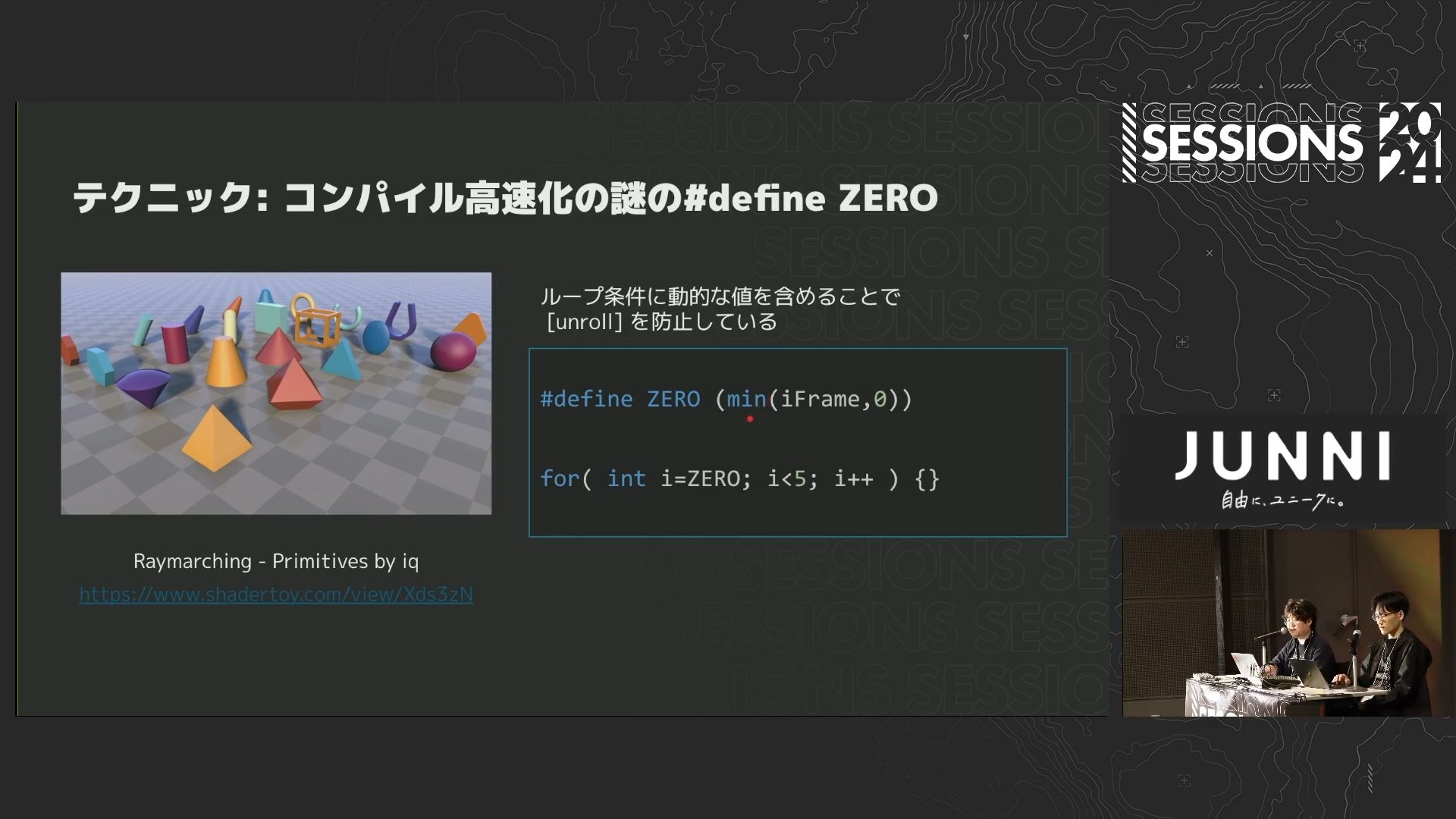
今回はレンダリング方程式のcos項に比例した重点的サンプリングのみ行いました。
レンダリング方程式のcos項に比例した重点的サンプリングを行うと、 確率密度関数で除算する処理でレンダリング方程式のcos項を打ち消すことができ、パストレーシング実装をシンプルにできます。
今回のシーンではIBL光源が支配的なため、cos項に比例した重点的サンプリングのみで少ないサンプリング数でレンダリング結果が収束しましたが、 光源が小さいシーンだと分散が大きいために収束が遅くなってしまいます。
来年までにはNext Event Estimationに挑戦してみたいです。
並列処理
並列処理もレイトレにおいては超重要です。
今回の実行環境は64コアのCPUなので、並列処理しないと計算リソースを全体の1/64しか使うことができません。
Rustの標準ライブラリのstd::threadでも並列化はできるのですが、
CPUのコア数に応じてスレッドプールを作ったり、適切にスケジューリングする部分はプログラマーが頑張る必要がありました。
Rayonという並列処理のライブラリを利用すれば、面倒なスケジューリングを自動でやってくれそうだったので、これを採用しました。
並列化の戦略
並列化の戦略を2通り試しました。

サンプリング数を固定化した並列化
まずは開発初期の並列化の戦略を説明します。
図の左のように時系列で行(y方向)ごとに処理し、列(x方向)の各ピクセルの計算を並列で行うようにしました。 各スレッド内で全サンプリングの計算して、最終的な画素値まで決定しました。
この戦略はサンプリング数を事前に決定する必要があるのですが、 サンプリング数を大きくしすぎると4:33の制限時間をオーバーしすぎる心配があり、 逆に小さくしすぎると計算リソースを使い切れなくなってしまいます。
今回のようにレンダリング時間がルールで決まっている場合は、あまり良い戦略ではありませんでした。
サンプリング数を動的に変更できる並列化
そこで、開発後半では並列化の戦略を変更しました。
図の右のように時系列でサンプリングごとに処理し、全ピクセルの計算を並列で行うようにしました。 直前の1サンプリングの所要時間から次のサンプリングで時間切れになることを予想したら、その時点でのサンプリング数の結果を出力して終了します。
これでサンプリング数を実行環境のスペックに応じて動的に調整できるようになりました。
しかし、この変更によって少しパフォーマンスが低下しました。 同じサンプリング数で比較すると、計算時間が5%程度増加してしまいました。 テクスチャをたくさん使ったシーンなので、キャッシュのヒット率が低下したのが原因かもしれません。
Rayonによる並列化をしたレンダリングの関数
これが実際のサンプリング数を動的に変更できる並列化をしたレンダリングの関数です。
Rayonでは、iter_mut()の代わりにpar_iter_mut()でイテレーターを作ると並列処理ができます。
元のコードをほとんど変更せずに並列化できるのは素晴らしいですね。
同じことをstd::threadで書こうとすると、かなりコードが複雑になると思います。
fn render(&mut self, scene: &SceneTrait, camera: &Camera, imgbuf: &mut ImageBuffer<Rgb<u8>, Vec<u8>>) -> u32 {
let resolution = Vector2::new(imgbuf.width() as f64, imgbuf.height() as f64);
let num_of_pixel = imgbuf.width() * imgbuf.height();
let mut accumulation_buf = vec![Vector3::zero(); num_of_pixel as usize];
// NOTICE: sampling is 1 origin
for sampling in 1..(self.max_sampling() + 1) {
accumulation_buf.par_iter_mut().enumerate().for_each(|(i, pixel)| {
let y = i as u32 / imgbuf.width();
let x = i as u32 - y * imgbuf.width();
let frag_coord = Vector2::new(x as f64, (imgbuf.height() - y) as f64);
*pixel += self.supersampling(scene, camera, &frag_coord, &resolution, sampling);
});
if self.report_progress(&accumulation_buf, sampling, imgbuf) {
return sampling;
}
}
self.max_sampling()
}
開発の振り返り
開発期間は1ヶ月弱でした。7/30くらいに着手して9/8の締め切りギリギリまで開発していました。
最低限のパストレが動くまでは1週間くらい、並列化やポリゴンの衝突判定のBVHによる高速化までは2週間くらいかかりました。
シーン調整していくうちに、バグや不具合が見つかったので、後半はシーン構築のための機能を追加しつつ、バグ修正をしていました。
Rustについて
去年はC++で開発したのですが、今年はRustでフルスクラッチで書き直しました。
Rustの所有権に慣れるまでは大変でしたが、トータルで見ればC++ではなくRustで開発して良かったと思います。
Rustの採用理由
こんな感じの理由でRustを採用しました。
- 実行時のパフォーマンスを重視している
- 並列処理が簡単にできて、実行時のオーバヘッドが低いことはレイトレには必須条件
- 高いポータビリティ
- MacでもWindowsでも、コードの変更なしに動かせる
- Webブラウザ上でも動かせる
- WebAssemblyの出力をサポートしている数少ない言語
- 他にサポートしているのはC++だけ?
- FirefoxのMollizaが中心に開発しているからなのだろうか
- WebAssemblyの出力をサポートしている数少ない言語
- 弊社(KLab)の社員が2人もRustでレイトレしており、困ったら教えてもらおうと思った
Rustの学習方法
Rustについて何も知らなかったので、まずは通勤中にプログラミング言語Rustを読んでRustの思想を学びました。
Rust Playgroundでブラウザ上でRustのコードを書いて実行できるので、 よく分からないところは実際に短いコードを書いて理解を深めました。
正直に言うと、Rustの学習コストはかなり高いと感じました。 Rustの予習に1週間かけましたが、いざコードを書いてみると所有権や型のサイズが不定などのコンパイルエラーに阻まれて、心が折れそうになりました。 特に所有権やライフタイムは自分には全く馴染みの無い概念で理解するのに苦労させられました。 また所有権を理解できたとしても、所有権のルールを守りながらコードを書くのは別問題だなと痛感しました。
はじめは大変でしたが、慣れてくればコンパイルエラーに阻まれることはなくりました。 所有権を守るために設計から見直すこともありましたが、結果的に所有権を意識することでコードがスッキリしました。
Rustは所有権という仕組みによってデータ競合を排除したり、ガーベジコレクタのない低オーバヘッドを実現しているので、 この辺は「学習コスト」対「安全性+実行時パフォーマンス」のトレードオフだろうと感じました。
C++の経験がある人はRustは何が新しいのか(基本的な言語機能の紹介) - いもす研 (imos laboratory)という記事を読むとRustの所有権の雰囲気を掴めると思いました。
Rustにはcargoというビルドツール兼パッケージ管理システムが標準搭載されていて、これはとても便利でした。
cargo runを叩くだけで、自動的にパッケージをフェッチし、依存関係を解決してビルドと実行ができます。
開発前半は通勤中にMacで開発して、開発後半は高スペックなWindowsデスクトップに開発環境を移行しました。 cargoのおかげでMacもWindowsも同じようにビルドができるので、開発環境を行き来するコストが全くありませんでした。
Rustのenum
Rustの特徴はたくさんあるのですが、列挙型は良いと思いました。 Cのenumとは違って、構造体やタプルのような各ヴァリアントに関連するデータを持たせることができるので、マテリアルのタイプの定義に便利でした。
#[derive(Clone, Debug)]
pub enum SurfaceType {
Diffuse,
Specular,
Refraction { refractive_index: f64 },
GGX { roughness: f64 },
GGXReflection { roughness: f64, refractive_index: f64 },
}
言語組み込みのnull許容型(Option)もenumで実装されていました。
Option<T>をSome(T)またはNoneをとるenumにすることでnullチェック漏れをコンパイル時の型のチェックでエラーとして検出できます。
この仕組はとても賢いですね。
pub enum Option<T> {
None,
Some(T),
}
HaskellのMaybeモナドと全く同じ仕組みなので、関数型言語の良いところも取り入れているのかなと思いました。
他にもリスト処理も充実していて好感が持てました。
RustのオススメIDE
個人的にRustの開発環境はIntelliJにRustのプラグインをインストールするのが最強だと思いました。 関数定義にジャンプできるのはもちろん、メソッド名の補完やリファクタリングなども普通に使えます。Vimは卒業しました。
デバッグ機能
レンダラーがある程度完成したら、シーンの編集作業がメインになっていきます。 しかし、シーンの確認のためにレンダリング結果を何分も待つのは時間の無駄です。
そこで直接照明のみ考慮し、屈折や反射をしない高速なレンダリングのモードを実装しました。
その他にも、法線・深度値・焦点面からの距離を表示するデバッグ機能を実装して、シーン編集の効率を向上させました。

まとめ
締め切り駆動開発でしたが、前から試したかったBVHなどを実装できたので良かったです。 Rustも手ごわかったですが、気合でなんとか習得することができました。
合宿のセミナーや雑談などでは、レンダリング分野の最先端で活躍されている方々にレイトレの知見をいただき、モチベーションが高まりました。 セミナーでは、大垣さんによる「20年間レンダラーを開発しているうちに考えたこと」、うしおさんによる「ファーのレンダリング」、Otsuさんによる「最新のPM/MCMC系手法」についてお話ししていただきました。 また、他の参加者にもNext Event Estimationの疑問点、双方向パストレーシングについて教えていただきました。
また、宿の料理が美味しかったことや、温泉から見える夕暮れの諏訪湖がとても綺麗だったことが思い出深いです。観光もとても楽しかったです。
運営・企画してくださったqさん、holeさん、本当にありがとうございました。
おまけ:制作の過程
モチベーション維持のために進捗をTwitterにアップロードするようにしました。
徐々にステップアップしていく様子を振り返ることができたので、やってよかったと思います。
資料公開したときのツイートです。
#レイトレ合宿 のためにRustで開発したパストレーサの紹介スライドです。 BVHによるポリゴンとの衝突判定を高速化、薄レンズモデルによる被写界深度などしました😆https://t.co/itDLyWNpFx
— がむ (@gam0022) 2017年9月10日
 gam0022.net's Tag Cloud
gam0022.net's Tag Cloud