
Google Search and Ray Tracing Were Driven by the Same Mathematical Algorithm: A 1998 Miracle in Computer Science
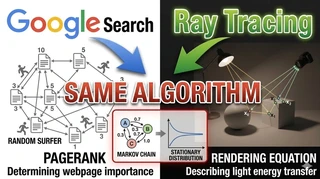
The “Key” That Connects Two Worlds That Seem Unrelated
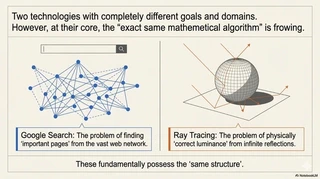
PageRank, which determines Google search rankings, and ray tracing, which produces realistic lighting in modern games and films, may appear to belong to completely different domains.
At first glance, they seem unrelated. But underneath, both are powered by the same mathematical algorithmic structure.
The problem of identifying important pages in a vast web of cross-referenced websites and the problem of computing accurate radiance in endlessly bouncing light within 3D space are fundamentally the same kind of problem.
Fields that look disconnected at the surface can converge into one coherent system of knowledge. Let us unpack this remarkable intellectual convergence that happened in 1998.
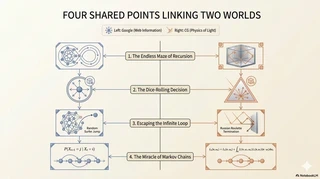
Shared Point 1: An Endless Recursive Maze of “Chicken or Egg?”
Google’s PageRank and the rendering equation in computer graphics share the same hard core challenge: a recursive (self-referential) definition.
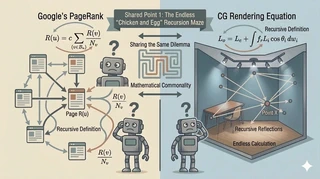
The PageRank Dilemma
The core idea of PageRank is simple: “A page linked from high-rank pages should also have high rank.”
But this contains a mathematical trap. To know the rank of page A, you need the rank of page B linking to it. To know page B’s rank, you need the ranks of pages linking to B, and so on. The definition becomes recursive (self-referential).
The original PageRank paper by Larry Page and others1 defines it mathematically as:
$$ R(u) = c \sum_{v \in B_u} \frac{R(v)}{N_v} $$Where:
- $R(u)$: PageRank value of page $u$
- $B_u$: Set of pages linking to page $u$
- $R(v)$: PageRank of each linking page $v$ (this is where recursion appears)
- $N_v$: Number of outgoing links from page $v$
- $c$: Normalization factor to keep total rank stable
To compute $R(u)$ on the left side, you need all the $R(v)$ values on the right side.
For the entire web graph, solving this massive “chicken-and-egg” system exactly is extremely expensive computationally.
The Rendering Equation Dilemma in CG
Computer graphics faces the exact same wall.
To determine brightness (radiance) at a point, you must sum light arriving from all directions. But that incoming light is itself light reflected from other points. So to compute point A, you need point B; to compute B, you need C; and the chain continues indefinitely.
The rendering equation, which describes physical light transport, defines outgoing radiance $L_o$ from point $x$ as a hemisphere integral2:
$$ L_o(x, \vec{\omega}_o) = L_e(x, \vec{\omega}_o) + \int_{\Omega} f_r(x, \vec{\omega}_i, \vec{\omega}_o) L_i(x, \vec{\omega}_i) \cos \theta_i d\vec{\omega}_i $$Where:
- $L_o(x, \vec{\omega}_o)$: Outgoing radiance from point $x$ toward direction $\vec{\omega}_o$
- $L_e(x, \vec{\omega}_o)$: Emitted radiance from point $x$
- $f_r(x, \vec{\omega}_i, \vec{\omega}_o)$: BRDF (reflectance function)
- $L_i(x, \vec{\omega}_i)$: Incoming radiance at $x$ from direction $\vec{\omega}_i$ (this is outgoing radiance from another point, hence recursion)
- $\cos \theta_i$: Incident-angle attenuation term
Just like PageRank, the left side appears recursively inside the right side.
Shared Point 2: The Breakthrough Was “Rolling the Dice”
To escape this infinite maze, both fields adopted a bold and elegant compromise: random trials.
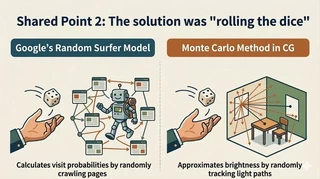
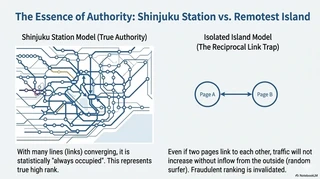
Google’s Random Surfer Model
Google introduced the random surfer model: imagine a surfer randomly following links forever. Then compute the long-run probability of being on each page.
For an intuitive explanation, a Japanese computer science radio episode3 compares PageRank to traffic flow in train networks.
Shinjuku Station analogy: Shinjuku has many train lines, so statistically it almost always has people passing through. This captures the nature of an authoritative page. High rank is not merely “many links” but high visitation probability.
Remote islands analogy: Even if two islands (pages) are connected to each other, if no one ever comes from the outside world, traffic never grows. This shows why mutual-link manipulation does not work well under the random-surfer viewpoint.
Monte Carlo in CG
In computer graphics, this is the Monte Carlo method. Instead of exactly integrating incoming light from every direction, we randomly sample a subset of directions and average them to estimate the integral.
In short, Monte Carlo is a method that uses random sampling to approximate otherwise intractable calculations.
Suppose you want the average temperature of a room. Exact computation would require measuring temperature at every point and integrating, which is impossible. So you pick random sample points and average them. As the number of samples $N$ increases, the estimate approaches the true room average.
Path tracing (ray tracing based on Monte Carlo light transport simulation) was founded by James T. Kajiya2 and brought to practical maturity by Eric Veach4.
In path tracing, rather than integrating all incoming light directions at a point, we sample a few random directions and average the incoming radiance from those directions.
Following each sampled direction recursively (and sampling again at the next bounce) builds full light paths.
Law of Large Numbers: More Trials, Closer to Truth

A natural question arises: If we sample only a few random directions, won’t the image become noisy and grainy?
That intuition is correct. With only a few paths, the output looks like old TV static (comparison images in this post were rendered with the author’s renderer5).
But then a powerful principle enters: the law of large numbers. Simulate hundreds or thousands of light paths per pixel and aggregate statistically, and something remarkable happens. Like rolling dice many times, random fluctuations average out. Noise gradually fades away, and the estimate converges to the physically correct value of real light transport.
So random sampling may look rough at first, but at large scale it reconstructs surprisingly realistic scenes. This convergence from apparent randomness to physical truth is exactly the strength of Monte Carlo methods.
This approach, simulating hundreds to thousands of paths per pixel and relying on statistical convergence, is essentially the same as PageRank. In both cases, a recursive definition is made tractable through probabilistic sampling.
Shared Point 3: Escaping the Infinite Maze
When recursion is involved, both algorithms face another common challenge: infinite loops (cyclic references).
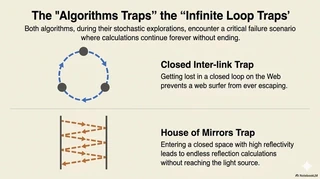
Damping Factor in Google
If a random surfer gets trapped in closed loops or tightly interlinked clusters, they may never leave. The mathematical fix is the damping factor. With a fixed probability (often about 15%), the surfer stops following current links and teleports to a random page. This prevents lock-in and enables a proper global steady-state ranking.
Russian Roulette in CG
An analogous mechanism exists in path tracing: Russian roulette.
In highly reflective scenes (like mirrors facing mirrors), rays could bounce forever. Russian roulette probabilistically terminates paths to keep computation finite.
This is not a careless “just drop paths” trick. If continuation happens with probability $P$ and termination with probability $1-P$, then surviving paths are reweighted by dividing their contribution by $P$ to preserve unbiasedness.

Think of a gambling analogy. 100 players each start with USD 1,000 in chips. Rule: with 1/2 probability you lose all (USD 0), with 1/2 probability you win and become USD 2,000.
Result: 50 players end at USD 0, 50 at USD 2,000. Total money is $50 \times 0 + 50 \times 2000 = 100,000$, so the average remains $100,000 \div 100 = 1,000$ per player. Individual outcomes split dramatically, but the system-wide expected energy stays exactly conserved.
The same symmetry holds in light transport. Even if 50% of paths are terminated, doubling the contribution of surviving paths preserves total expected light energy over the image.
What looks like a rough probabilistic shortcut is, in fact, mathematically precise global accounting.
Shared Point 4: The 1998 “Miracle” and Markov Chains

What is striking is when these two fields arrived at the same mathematical destination.
In 1998, the PageRank paper by Larry Page and colleagues1 and Eric Veach’s seminal PhD thesis on Monte Carlo light transport4 were published in the same year.
Researchers in different domains converged on the same mathematical summit: Markov chains.
A Markov chain is, simply put, a process where the next state is determined probabilistically from only the current state, independent of the past.
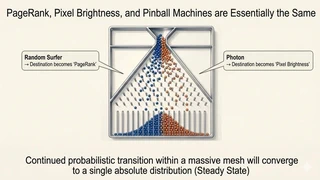
For intuition, imagine a giant pinball machine. Drop many balls from the top. At each peg, whether a ball goes left or right is probabilistic. Balls bounce randomly as they descend.
If you keep dropping millions of balls, the occupancy ratio among bottom pockets eventually stabilizes to a fixed proportion.
In mathematics, this is the stationary distribution.
The web link graph and light reflection in 3D scenes are both versions of this same pinball machine.
- PageRank: Throw random-surfer balls into the web graph. The long-run probability of ending up at each page is the stationary distribution, i.e., its rank.
- Path tracing: Throw light-particle balls into the scene. Their distribution after stochastic reflections determines accurate pixel radiance.
Both are the same mathematical question: If we let probabilistic transitions continue over a network, what distribution do we converge to?
At-a-Glance Comparison
| Item | PageRank (Google) | Path Tracing (CG) |
|---|---|---|
| Target | Importance of information on the web | Radiance of light in 3D space |
| Challenge | Recursive rank definition and cyclic references | Recursive rendering equation and infinite reflections |
| Solution | Random surfer + teleportation (damping factor) | Monte Carlo + Russian roulette |
| Goal | Estimate steady-state importance | Converge to steady-state radiance |
| Essence | Time spent by random walks = statistical importance | Randomly traced paths = statistical radiance |
The 1998 Algorithms Still Matter in the AI Era
As of 2026, AI has advanced rapidly. Google Search incorporates AI-based semantic understanding6, and ray tracing workflows use powerful AI denoising methods such as NVIDIA DLSS 3.5 ray reconstruction7.
We now live in an era where AI can infer a plausible answer from fewer samples, without waiting as long for pure law-of-large-numbers convergence.
But AI has not replaced the underlying mathematics. No matter how smart models become at interpreting context or removing noise, the definition of “ground truth” used for learning and inference still depends on these 1998-era algorithms.
What other hidden common laws might be waiting in the ocean of seemingly unrelated fields? Behind tomorrow’s new technology, another mathematical thread connecting distant domains may already be there.
Addendum: Does Google Actually “Roll Dice” in Practice?
So far, we explained PageRank using the random-surfer story of random walking. Technically, an important nuance is needed.
The random-surfer model is primarily an interpretive model that helps humans intuitively understand and justify the PageRank metric.
In production, Google does not simulate each surfer by rolling literal random dice. Instead, PageRank is typically computed deterministically as an eigenvector problem, often via iterative power methods.
In contrast, Monte Carlo sampling is used in CG path tracing because light-path combinations are effectively near-infinite and cannot be realistically flattened into one explicit matrix at web scale.
Why Does an Eigenvector Give a Stay Probability?
You might wonder: “How can matrix math produce probabilities?” The key intuition is to view the matrix as how one step changes the distribution.
Let $R$ be a vector whose entries are the proportions of surfers currently staying on each page. Multiplying by a matrix simulates this transition: everyone moves simultaneously from current pages to next pages by following links.
The matrix $A$ is a huge square matrix over pages. In the original formulation, if page $u$ links to page $v$, then entry $A_{u,v}$ is assigned $1 / (\text{number of outgoing links from page } u)$. This value represents the transition probability from page $u$ to page $v$.
So $A$ is a full description of web-wide transition rules.
If we repeatedly multiply by this matrix (repeat transitions), the distribution eventually stops changing and reaches a stable state where another transition leaves proportions unchanged.
$$R = cAR$$- $c$: normalization factor corresponding to the eigenvalue
In this equation, when multiplying by matrix $A$ (transition rule) does not change the direction of vector $R$ (stay ratio/PageRank), that is exactly an eigenvector in linear algebra and a stationary distribution in probability theory.
One approach is deterministic, the other explicitly stochastic. But mathematically, both solve the same objective: finding the stationary distribution of a Markov chain.
Addendum 2: Released the YouTube version
L. Page, S. Brin, R. Motwani & T. Winograd (1998). The PageRank Citation Ranking: Bringing Order to the Web ↩︎ ↩︎
Kajiya, J. T. (1986). The Rendering Equation. SIGGRAPH ‘86 ↩︎ ↩︎
Yuru Computer Science Radio (2022). “Random Surfer,” the Clever Idea Behind Google Search【Google2】#43 ↩︎
Veach, E. (1998). Robust Monte Carlo Methods for Light Transport Simulation ↩︎ ↩︎
gam0022 (2017). three.js webgl - pathtracing sandbox ↩︎
Google. How Search Works | Ranking Results ↩︎
NVIDIA (2023). Ray Reconstruction: Deep Learning Super Sampling (DLSS) 3.5 ↩︎
Related Posts
Google検索とレイトレーシング、実は同じ数理アルゴリズムで動いていた。1998年に起きた「計算機科学の奇跡」
一見無関係に見える「ページランク」と「パストレーシング」。その根底にある数学的共通点と、再帰的な定義を解き明かすランダムサンプリングの魔法について解説します。

レイトレ合宿10でポータルをテーマにしたアニメーションを作成しました
10月11日(金)~10月13日(日)に熱海の初島で開催されたレイトレ合宿10に参加しました。

レイトレ合宿9で4次元立方体をテーマにしたアニメーションを作成しました
9月1日(金)~9月3日(日)に日蓮宗大本山清澄寺で開催されたレイトレ合宿9に参加しました。



Books
ブログ執筆者の著書


