
Google検索とレイトレーシング、実は同じ数学で動いていた。1998年に起きた「計算機科学の奇跡」
全く別物に見える2つの世界を繋ぐ「鍵」
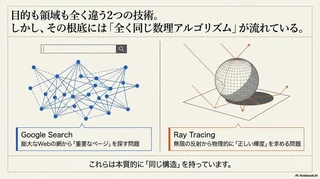
Google検索の順位を決める ページランク と、最新ゲームや映画を彩る本物のようなリアルな光の表現を生み出す レイトレーシング。
一見すると無関係な2つの領域ですが、その根底には 同じ数理アルゴリズム が流れています。
膨大なWebページ相互参照の網から 重要なページ を特定する問題も、3D空間上で無限に反射し続ける光の中で 正確な輝度 を求める問題も、本質的には同じ構造を持っています。
一見バラバラな領域が、一つの「知の体系」へと収束していく。1998年に起きた知的な大いなる合流について、紐解いていきましょう。
共通点1:終わりのない「鶏が先か、卵が先か」の再帰の迷路
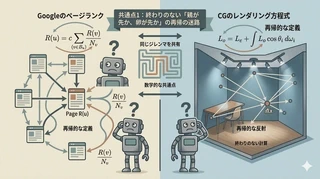
Googleの ページランク と、光の挙動を記述する レンダリング方程式 。この両者が抱える共通の難問、それは 再帰的な定義(自己参照) という数学的な迷宮です。
Googleのページランクのジレンマ
Googleの重要度計算の核となる「ページランク」の考え方はシンプルです。 「ランクの高いページからリンクされているページは、ランクが高い」 というものです。
しかし、ここに数学的な難問が潜んでいます。ページAのランクを知るには、リンク元であるページBのランクを知る必要があります。しかし、そのページBのランクを知るためには、さらにそのリンク元のランクを知る必要があり……というように、定義が 再帰的(自己参照的) になっています。
ラリー・ペイジらによるPageRankの元論文1にページランクの数学的な定義が記述されています。
$$ R(u) = c \sum_{v \in B_u} \frac{R(v)}{N_v} $$各変数の意味は以下の通りです。
- $R(u)$:ページ $u$ のページランク値
- $B_u$:ページ $u$ にリンクしているページの集合
- $R(v)$:ページ $u$ へリンクしている個々のページ $v$ のページランク。これが 再帰を意味する
- $N_v$:ページ $v$ から出ているリンクの総数
- $c$:全ページのランクの総和を一定に保つための正規化係数
ページランク $R(u)$ (式の左辺)を知るためには、そのページにリンクしている全ページのページランク $R(v)$ (式の右辺)を確定させる必要があります。
ウェブ全体という膨大なネットワークにおいて、この巨大な「鶏が先か卵が先か」という連立方程式を厳密に解くことは、計算コストの面で極めて困難です。
CGのレンダリング方程式のジレンマ
一方、CG(コンピュータグラフィックス)のレンダリング計算も、全く同じ 再帰的な定義 の壁に直面しています。
ある地点の明るさ(輝度)を決めるには、周囲のあらゆる方向から届く光を合計しなければなりません。 しかし、その届く光の強さは、「別の場所で反射してきた光」です。 つまり、地点Aの明るさを決めるには地点Bの明るさが必要で、地点Bの明るさを決めるには地点Cの明るさが必要になる……という、無限の連鎖(再帰)が発生します。
物理的な光の挙動を示す レンダリング方程式 は、ある点 $x$ から出る輝度 $L_o$ を半球上の積分として定義します2。
$$ L_o(x, \vec{\omega}_o) = L_e(x, \vec{\omega}_o) + \int_{\Omega} f_r(x, \vec{\omega}_i, \vec{\omega}_o) L_i(x, \vec{\omega}_i) \cos \theta_i d\vec{\omega}_i $$各変数の意味は以下の通りです。
- $L_o(x, \vec{\omega}_o)$ :点 $x$ から方向 $\vec{\omega}_o$ へ放射される輝度
- $L_e(x, \vec{\omega}_o)$ :点 $x$ 自体が発する輝度(自発光)
- $f_r(x, \vec{\omega}_i, \vec{\omega}_o)$ :BRDF(反射の特性を決める関数)
- $L_i(x, \vec{\omega}_i)$ :点 $x$ に方向 $\vec{\omega}_i$ から入射する輝度。これが 「別地点から放射された $L_o$」であることが再帰を意味する
- $\cos \theta_i$ :入射角による減衰
これはページランクと同じように、右辺に左辺がある再帰的な定義です。
共通点2:解決策は「サイコロを振ること」だった
この無限の迷路を突破するために導入されたのが、統計的な「ランダムな試行」という、大胆かつ知的な割り切りでした。

Googleのランダムサーファーモデル
Googleは、ネットの海を無作為に漂う ランダムサーファー を想定しました。サーファーがリンクをランダムに辿り続け、無限に繰り返した結果として「あるページに滞在している確率」を算出します。
直感的な理解を深めるため、PageRankの核心を「交通網や駅の利用者数」に例えて解説したゆるコンピュータ科学ラジオの動画3が参考になります。
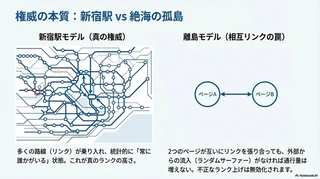
新宿駅の例え:新宿駅のように多くの路線が乗り入れている場所は、統計的に 常に誰かがいる 状態になります。これが 権威あるページ の本質です。ランクの高さは、単にリンク数の多さではなく、統計的に多くのサーファーが訪れる確率 によって決まります。
離島の例え:2つの島(ページ)が互いに橋(リンク)を架けて行き来していても、外の世界から誰も来なければ、その島の通行量は増えません。 これは 相互リンクによる不正なランク上げ が、ランダムサーファー(=外から来る人)の視点では無効であることを示します。
CGのモンテカルロ法
CGの世界では、これを モンテカルロ法 と呼びます。あらゆる方向から来る光の積分を真面目に計算する代わりに、いくつかの方向を ランダムに選び(サンプリング)、その平均をとることで近似値を導き出します。
モンテカルロ法とは、一言で言えば 乱数を使ったサンプリング(試行)によって、複雑な計算の近似値を求める手法 です。
例えば、ある部屋の平均気温を知りたいとします。厳密に求めるなら、部屋中のすべての点の温度を測定して積分しなければなりませんが、これは不可能です。 そこで、部屋の中で ランダムに数カ所(サンプリング点)を選び、その場所の温度の平均を計算します。サンプリングする地点(サンプル数 $N$ )を増やせば増やすほど、この平均値は部屋全体の真の平均気温に近づいていきます。
モンテカルロ法を用いたレイトレーシング(光輸送シミュレーション)の集大成がエリック・ヴィーチ(Eric Veach)の博士論文4に書かれています。
パストレーシング(モンテカルロ法を用いたレイトレーシング)においては、ある点で見える明るさを決めるために、周囲のあらゆる方向から来る光(積分)を計算する代わりに、いくつかの方向をランダムに選び(サンプリング)、その方向から来た光の強さを平均する という処理を行います。
このランダムに選んだ方向をさらに追跡していく(そこでもまたランダムに方向を選ぶ)ことで、光の経路(パス)が形成されます。
大数の法則:試行回数を増やすほど「正解」に収束する
しかし、ここで自然な疑問が生じます。ランダムに数個の方向を選んで光を計算したら、ノイズだらけのザラザラした画像になってしまうのではないか? という問題です。この直感は正しく、実際に、わずか数本の光の経路をランダムに選んだだけでは、昔のテレビの砂嵐のようなノイズに満ちた画像が出力されます。
ところが、ここで非常に興味深い数学の大原則が登場します。それが 大数の法則 です。1ピクセルあたり数百、数千という膨大な数の光の経路をシミュレートし、その統計を取っていくと、奇跡のようなことが起きます。サイコロを何万回も振るような状態で、振る回数が少ないときは当然ばらつきが出ますが、膨大な回数をこなして平均を取ると、ノイズが次々とスーッと消えていきます。そして最終的に、現実の光の物理法則が示す真の値にピタリと収束します。
つまり、一見いい加減に見えるランダムなサンプリングも、圧倒的な数をこなすことで、驚くほどリアルな現実の光景が画面上に浮かび上がってきます。適当に思えるランダム処理が、大数の法則という数学の力によって、実世界の物理法則に見事に収束するという、このメカニズムこそがモンテカルロ法の強みなのです。
1ピクセルあたり数百〜数千のパスをシミュレートし、その統計をとることでリアルなCGを実現するこのアプローチは、実のところページランクと全く同じ手法です。すなわち、どちらも 「再帰的な定義」を「確率的なサンプリング」で乗り越えている のです。
共通点3:無限の迷路を抜ける仕組み
再帰的な探索を行う際、どちらのアルゴリズムも 無限ループ(循環参照) という共通の課題に直面します。
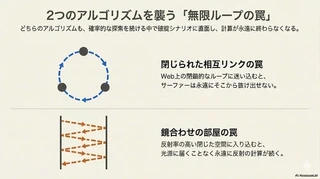
Googleのダンピングファクター
ランダムサーファーがウェブを巡回する際、同じページ同士が相互にリンクしていたり、閉じたループの中に迷い込んだりすると、そこから抜け出せなくなる可能性があります。 これを数学的に解決するのが ダンピングファクター( $d$ ) です。 サーファーはときどき(一定の確率 $1-d$ )、現在のリンクを辿るのをやめて全く別のページへランダムに テレポート します。 これにより、特定のループに捕らわれずウェブ全体の定常状態を正しく評価できるようになります。
CGのロシアン・ルーレット
同様の仕組みは、パストレーシングの世界にも存在します。反射率の高い壁による「鏡合わせの部屋」のように、光のレイが永久に反射し続けて追跡が終わらない状況を回避するため、 ロシアン・ルーレット という手法が使われます。
これは単に「運が悪ければ計算を捨てて終わり」という雑な処理ではありません。 例えば、確率 $P$ で反射を継続し、確率 $1-P$ で打ち切るとします。このとき、生き残ったパスの寄与を 継続確率 $P$ で割る ことで、統計的なバランスを取ります。
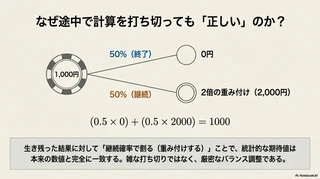
この仕組みを理解するため、ギャンブルの例えを考えてみましょう。100人が1,000円分のチップを持ってゲームに参加します。ルールは単純で 「1/2の確率で失敗して0円になるが、勝てば2,000円になる」 という高リスク・ハイリターンなゲームです。
結果として、50人は失敗して0円になり、50人は2,000円を手にします。全体の合計金額は $50 \times 0 + 50 \times 2000 = 100,000$ 円。つまり、1人当たりの平均は依然として $100,000 \div 100 = 1,000$ 円のままです。個人の運命は0か2倍かに明確に分かれていても、システム全体の統計的なエネルギーはプレイ前と全く変わらない のです。
この対称性が、光の計算でも完全に成立します。個々の光の粒子が、50%の確率で途中で 消滅 されても、生き残った光のエネルギーを2倍に 増幅 することで、画面全体の光のエネルギー総和は 数学的に完璧に保存される のです。
一見いい加減に見える確率の操作が、全体の辻褄を完璧に合わせているというのは、アルゴリズム設計の真骨頂と言えるでしょう。
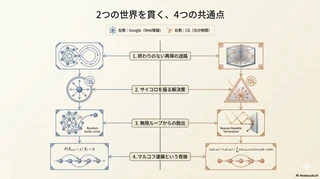
共通点4:1998年に起きた「計算機科学の奇跡」とマルコフ連鎖
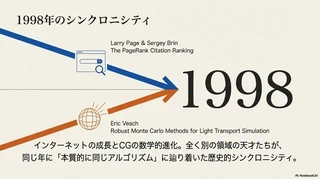
驚くべきは、この2つの領域が「同じ数学的ゴール」に辿り着いた時期です。
1998年。ラリー・ペイジらによるPageRank論文1が発表されたその同じ年、エリック・ヴィーチ(Eric Veach)によるモンテカルロ法を用いたレイトレーシングの集大成となる論文4が発表されました。
異なる領域で格闘していた研究者たちが、同じ時期に マルコフ連鎖 という数学の頂で出会ったのです。
マルコフ連鎖とは、ごく簡単に言うと 「現在の状態だけを基に、次の状態が確率的に決まるプロセス」 です。過去がどうであったかは一切関係ありません。
この概念を直感的に理解するため、巨大な ピンボールマシン を想像してみましょう。上から無数のボールを落とすと、ボールが釘に当たって右に行くか左に行くかは確率で決まります。ランダムにカン・カン・カンと跳ね返りながら落ちていきます。
そのボールを何百万個も落とし続けたとき、最終的に下にある複数のポケットのどこにどれくらいの割合でボールが積み上がるか。最初はバラバラでも時間が経つと一定の割合に落ち着きます。
これを数学の言葉で 定常分布(stationary distribution) と呼びます。
ウェブのリンク構造も、3D空間での光の反射特性も、本質的にはこの巨大なピンボールマシンと同じです。
- ページランク :ランダムサーファーというボールをウェブに放り込んだ時、最終的にどのページに落ち着く確率が高いか。それが定常分布であり、各ページのランクです。
- パストレーシング :光の粒というボールをシーンに放り込んだ時、反射を重ねながら最終的にどこに集約するか。その分布が各ピクセルの正確な輝度を決定します。
どちらも 「網目状ネットワークの中にボールを放り込み、確率的に遷移させ続けた結果、何が起こるか」 という同じ数学的問題なのです。
一目でわかる比較まとめ
| 項目 | ページランク (Google) | パストレーシング (CG) |
|---|---|---|
| 対象 | Web上の情報の重要度 | 3D空間上の光の輝度 |
| 課題 | ページランクの再帰的な定義と循環参照 | レンダリング方程式の再帰的な定義と無限反射 |
| 解決策 | ランダムサーファー + テレポート(ダンピングファクター) | モンテカルロ法 + ロシアン・ルーレット |
| 目的 | 定常状態(重要度)の推定 | 定常状態(輝度)の収束 |
| 本質 | ランダムに歩き回った時間=統計的な重要度 | ランダムに追跡したパス=統計的な輝度 |
AI時代でも1998年のアルゴリズムは生きている
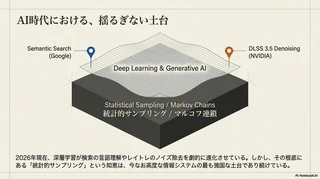
2026年の現在、AI技術は急速に進化しています。Google検索にはAIによるセマンティック理解5が導入され、レイトレーシングの世界でもAIを用いた強力なデノイジング技術6が活用されています。大数の法則による収束を待たずとも、AIが少ないサンプルから「正解」を推測できる時代になりました。
しかし、AIは根本の数学を置き換えたわけではありません。AIがどれほど賢く文脈を読み取ったり、ノイズを除去したりできるようになっても、その学習や推論の指標となる定常分布を定義しているのは、今でもこの1998年のアルゴリズムです。
一見バラバラに見える情報の海の中に、次に発見される「共通の法則」は何だと思いますか? あなたが明日手にする新しいテクノロジーの裏側にも、全く別の分野と繋がる「数学の糸」が隠れているのかもしれません。
L. Page, S. Brin, R. Motwani & T. Winograd (1998). The PageRank Citation Ranking: Bringing Order to the Web ↩︎ ↩︎
Kajiya, J. T. (1986). The Rendering Equation. SIGGRAPH ‘86 ↩︎
ゆるコンピュータ科学ラジオ. (2022). Google検索を支える巧妙なアイデア「ランダムサーファー」【Google2】#43 ↩︎
Veach, E. (1998). Robust Monte Carlo Methods for Light Transport Simulation ↩︎ ↩︎
Google. Google 検索の仕組み | 検索結果のランキング ↩︎
NVIDIA. (2023). Ray Reconstruction: Deep Learning Super Sampling (DLSS) 3.5. ↩︎
Related Posts

レイトレ合宿10でポータルをテーマにしたアニメーションを作成しました
10月11日(金)~10月13日(日)に熱海の初島で開催されたレイトレ合宿10に参加しました。

レイトレ合宿9で4次元立方体をテーマにしたアニメーションを作成しました
9月1日(金)~9月3日(日)に日蓮宗大本山清澄寺で開催されたレイトレ合宿9に参加しました。




Books
ブログ執筆者の著書


